









Within our company, we are very enthusiastic about our Hackathons. It is a time to get together with clients and focus fully on innovation, a time when we can experiment with new technologies and use them for prototypes that we can apply to specific needs. As techies, we are always thrilled to work with new technologies we feel have value for the market. We are proud to share Flui Technologies article on how they perceived the Yonder Hackathon and what they have created with the team.
Before we post the article, let us introduce the company. Flui Technologies is a software solution provider for the energy sector. Since 1990, they have provided the software infrastructure and services to enable market competition, smart metering, and supplier integration. Their solutions are built on a heritage of deep industry knowledge, coupled with technical innovation and strong success-focused delivery.
Here is the article:

Flui was at Yonder’s 2024 hackathon event. We worked with one of the hackathon teams to develop and evaluate the prototype of the Flui Wiki Bot, a tool aimed at improving our internal knowledge management capabilities by providing semantic search and accurate question answering. This tool addresses the challenge of information fragmentation by leveraging cutting-edge open source Large Language Models (LLMs), Embedding models, and Vector Databases as part of a Retrieval-Augmented Generation (RAG) application.
Context and Objectives
The project’s core objective was to create a Wiki Bot by implementing an effective RAG pipeline using open source tools while running everything within our own secure cloud environment where we can limit access to ensure the protection and integrity of our confidential/proprietary data.
The Wiki Bot was designed to handle natural language queries using a primary LLM which can be selected from available models. The process:
- The user’s query (input prompt) is used to complete a semantic search of our vector database.
- The user’s original prompt is enriched (appended) with the most relevant context extracted from the vector DB.
- The primary LLM is then able to provide the best, most accurate response possible.
The following diagrams provide a good overview of the most basic RAG pipeline architecture:
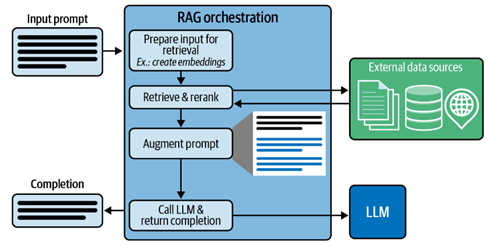
Image 1: RAG Highest Level Architecture
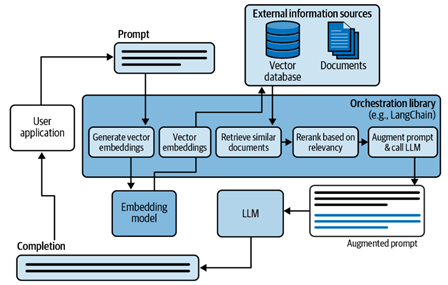
Image 2: RAG Less-Abstract Overview
Technical Overview
- LLM Deployment: We hosted the primary LLM on an Amazon SageMaker instance, which allows for robust inference capabilities while meeting our security and access requirements.
- Embedding and Vector DB: We implemented a tried and tested open source Embedding model called BG Large to convert proprietary documents into a semantically searchable format within a Chroma DB, our chosen open-source Vector Database. We used an embedding approach that respects markdown and sentence boundaries to maintain context integrity.
- Semantic Search Process: User prompts were used to conduct a semantic search in the Vector DB, retrieving relevant context to enable the generation of accurate responses. Context retrieved was ranked based on its semantic relevance to the original prompt.
- Response Generation: We enhanced the LLM’s capability by appending retrieved context chunks to the user’s original prompt, improving the quality and precision of the answers provided.
Image 3: SageMaker Studio
Experience at the Hackathon
The hackathon environment was intense and exhilarating. As part of the SageMakers team, we tackled complex tasks such as configuring AWS SageMaker, embedding documents into a Vector DB, and integrating token streaming. The team skilfully adapted to the quirks of the newly released Llama 3 LLM to successfully implement a RAG pipeline crucial for the Wiki Bot’s functionality. The Yonder office was abuzz with energy, and teams experienced many highs and lows in learning new skills and unlearning old misconceptions.
We encountered and overcame several challenges; including devising a workaround for a release day bug in the Llama-3 model that caused it to endlessly ramble to fill the context window.
Reflections on the Hackathon
The hackathon was an invaluable learning experience, expanding our technical expertise and problem-solving skills. The rapid development of a functional prototype under an extremely tight deadline highlighted the importance of agility and collaboration. Also, there were loads of delicious Romanian food, unlimited energy drinks, and coffee (or “holy water” as it’s known at Yonder).
Expanded Scope
Once we met our initial prototype scope, we added some additional functionality. Inspired by how capable Meta’s open source Llama-3 was, we introduced a tab to our prototype enabling colleagues to use an AI Assistant and a separate tab for open source LLMs fine-tuned for natural language to SQL tasks, enhancing support for client queries and business intelligence solutions. The intention was to add functionality which could provide immediate benefit to colleagues at Flui, given the amount of time it would likely take to further refine the RAG pipeline would exceed the time we had left at the hackathon.
Value Brought Back to Flui
The Flui Wiki Bot prototype is fully owned by Flui Technologies and is ready for further development and deployment. It will be utilised by colleagues as part of a limited trial to assess its value. While the RAG pipeline needs more investment and development to extend beyond a single document, the newly added features such as the AI Assistant and the SQL DB Bot are ready to provide immediate value. Yonder has agreed to package the prototype into Flui’s GitHub repository to facilitate redeployment, and all the Jupyter notebooks are saved locally on the Flui OneDrive.
Further development of this prototype will not only enhance our ability to manage and utilise internal knowledge but also demonstrate Flui’s commitment to data security and technological innovation.
When deployed, the AI Assistant and SQL BI Bot could provide immediate benefits in areas governed and prohibited by our corporate policy regarding using confidential/proprietary information with consumer AI tools like ChatGPT.
Future Directions and Improvements
Short-term goals include enhancing the embedding and retrieval processes by experimenting with different models and chunking approaches to optimise the quality of responses. Long-term ambitions focus on implementing caching mechanisms for faster response times and ensuring scalability through AWS Elastic Load Balancing.
Closing Thoughts
This hackathon not only demonstrated our team’s dedication and skill in developing sophisticated systems within stringent timelines but also set the stage for ongoing enhancements and innovations at Flui Technologies. With these developments, we aim to further leverage cutting-edge AI solutions to transform our business operations and decision-making processes. As always, the true test of our prototype will be how it performs and how useful colleagues find it in practice.
– Jason Jackson, Product Owner, Flui R&D
Click here to read the article on Flui Technologies website.
If you want to book a free consultation with our Head of Innovation, Paul Cirstean, please fill in the form below the article.
Here are some other articles on AI for those of you who are interested:
Mirror, mirror on the wall – AI innovation lab video
AI – friend or foe of the DevOps community
Yonder’s AI innovation lab projects
Banner by Appolinary Kalashnikova on Unsplash
Book your free
1-hour consultation session
Yonder offers you a 1-hour free consultation with one of our experts. This is for software companies and enterprises and focuses on any concerns or queries you might have.
STAY TUNED
Subscribe to our newsletter today and get regular updates on customer cases, blog posts, best practices and events.